![]() We often develop highly available, scalable systems for different markets like fintech, adtech and internet services.
Those systems are developed with industry proven, solid open source products and architectures which efficiently solve
common demands. Specifically, there are a lot of well-known players here, like lambda-architecture for streaming data
processing or microservice architecture for horizontally scalable high performance services, noSQL solutions like
Redis, Aerospike, MongoDB, message brokers (Kafka, RabbitMQ), distributed coordination and discovery servers (Apache
Zookeeper, Consul) and others. Those building blocks guarantee successfull application delivery in most of the cases
and project team doesn’t spend development efforts for delivery of low level components, spending most of the time for
the requirements development.
We often develop highly available, scalable systems for different markets like fintech, adtech and internet services.
Those systems are developed with industry proven, solid open source products and architectures which efficiently solve
common demands. Specifically, there are a lot of well-known players here, like lambda-architecture for streaming data
processing or microservice architecture for horizontally scalable high performance services, noSQL solutions like
Redis, Aerospike, MongoDB, message brokers (Kafka, RabbitMQ), distributed coordination and discovery servers (Apache
Zookeeper, Consul) and others. Those building blocks guarantee successfull application delivery in most of the cases
and project team doesn’t spend development efforts for delivery of low level components, spending most of the time for
the requirements development.
Sometimes, however the tasks occur which hardly can be solved with generic, well known building blocks mentioned before, and the need takes place in the development of the middleware or the search of appropriate very specialized means. The story is about our experience solving such kind of tasks.
The Task
In one of the projects the team had a quite specific task which required implementing of the strictly-ordered, distributed, horizontally scalable, reliable queue for states with repeating replay support. Basically, it is a commit log structure which usually can be found in every sophisticated DBMS. But the task required it distributed, scalable and reliable because of using it for the implementation of “exactly-once” processing.
The main requirement to the commit log — strictly ordered changes fixation, thus the structure guarantee, all the consumers will observe the records in the correct way, where the term “correct” means that the records are observed in the same order they were placed by producers. Commit logs have broad adoption in the systems which provide high performance concurrent write access to the set of objects. A typical example of such structure is
LinkedBlockingQueuein Java.
In parallel computing, the problem occur when the set of agents distribute states changes among the set of objects observed by the consumers and it’s required every of the consumers eventually to observe the same object state. This is sophisticated task and there are approaches to achieve the result. The problem example is displayed at the picture:
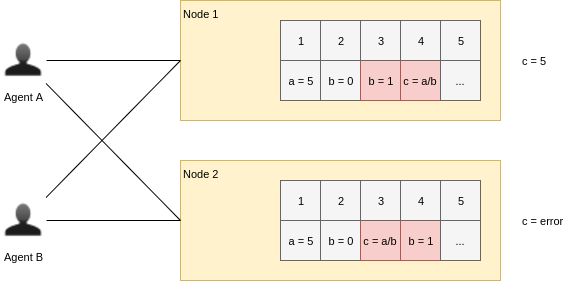
There are approaches to tackle with the problem. The first and least performant one is the use of distributed locking service like Apache Zookeeper to lock the objects, change their state and unlock after. This approach guarantees the ordering but very slow because changes are applied immediately and all the agents have to acquire the lock to get an access to the state. Thus it doesn’t suite well for high performance applications. The best one uses distributed, replicated, highly available commit log service.
We had that problem in the project and we needed to make it work very fast, so we were unable to use distributed locking service and shared mutex to solve it and thus we wanted to implement the best approach with distributed, replicated,highly available commit log service.
We were required to develop a high performance replicated leader-followers system with local state database implemented with RocksDB with easy recovery facility. An abstract diagram of the proposed solution is displayed at the picture:
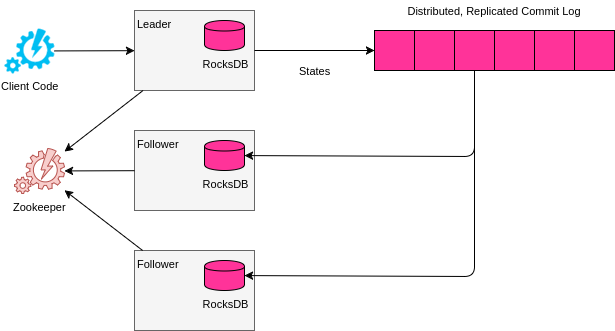
The main problem within the task is the development of a distributed replicated commit log system.
Distributed Replicated Commit Log
We already had an implementation for the commit log but it was local and it was quite a lot of work to implement changes required to support it in a distributed and reliable way.
You might wonder why just not to use Apache Kafka for the task. Actualy, it’s almost the solution, but Kafka has lack of task-critical features makes it unsuitable within the task. There two of them basically:
- write operations confirmation;
- order and uniqueness guarantee.
In the most cases Kafka is just fine and works as expected, but in the situations of network failures it doesn’t guarantee the messages are still unique. It is caused by the Kafka’s fire-and-forget nature which is optimized for maximizing of the bandwidth but not reliability.
Fortunately, analyzing and comparing the alternatives we found that the suitable solution existed, but we hadn’t known about it. It is Apache BookKeeper. Moreover it was implemented ideologically and technologically in the way we would like doing it, with Apache Zookeeper, Java and Netty. As a result, we initiated the research phase of Apache BookKeeper to ensure it fits our needs.
The rest of the article explains core concepts of Apache BookKeeper and their influence on the applications.
Apache BookKeeper
Now we would like to explain the principles and approaches used by Apache BookKeeper when developing reliable, scalable, replicated commit logs. The product is not well known one but there are famous users exist:
First of all, let’s take a look at the conceptual Apache BookKeeper architecture displayed in the slide:
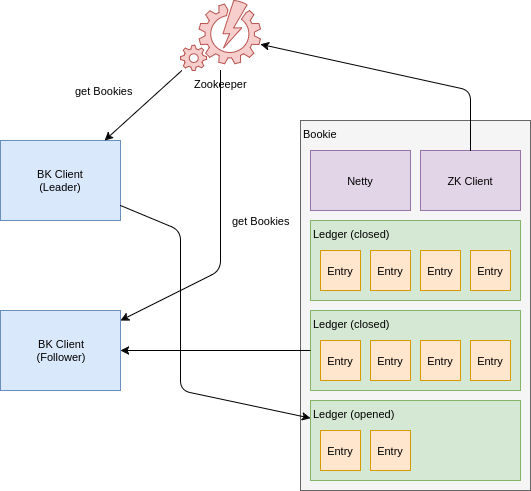
Key elements of Apache BookKeeper:
- Bookie — server which keeps actual commit log records;
- Ledger — volume which organizes commit records into single, ordered sequential structure and defines the replication set of Bookies where that ledger is stored;
- Ledger Entry — single entry which represents commit log record;
- BK Client — client-side java code used to append and read ledgers and ledger entries from Bookies;
- Zookeeper — Apache Zookeeper server, which stores records about ledgers (Ledger id, Bookie servers where replicas of the Ledger are kept).
Let’s take a look at core elements in more depth which helps understanding of the Apache BookKeeper architecture and it’s data management approach.
Bookie
Bookie is a data storage server. Apache BookKeeper requires DevOps engineers to deploy and run a set of Bookie servers (at least 3 of them are recommended). The data are distributed among Ledgers, the distribution is flat, the system doesn’t support topological distribution (which might be a cool feature). Additional Bookie servers help to scale the system horizontally.
Ledger
A ledger is a volume which organizes commit records into sequential structure and replicated over the same servers. ledgers are ordered according to increasing identifiers of 64bit long integer. Zookeeper ledger record includes the information about all Bookie servers which hold the replica of the Ledger.
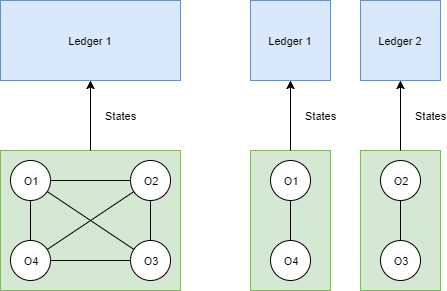
Important Limitatation #1: The only single writer can write into a ledger. Thus, a ledger is a basic scalability unit. If commit records influence co-dependent objects and objects set can not be split into several subsets then the system can not be scaled horizontally by distributing operations over several ledgers. In that case the performance is determined by the performance of a slowest Bookie server (and configured replication factor, but slightly, because BookKeeper clients writes in parallel). Scalability example is demonstrated in the following picture.
Ledgers are appended with new records either synchronously or asynchronously, every record has client-defined unique increasing record id, which helps implementing of asynchronous appending. BookKeeper guarantees that an operation with record id equal to N+1 will complete only and after all previous N operations completed. This is a very important property whci helps improve the performance of append operations in the cases even if the strictly ordered client code notification about completed operations is required.
Important limitation #2: Many readers are allowed to read from a ledger, but the reading is permitted only after a ledger is closed by a writer.
Two limitations mentioned above is quite tough and in certain circumstances narrow or even prevent the applicability of Apache BookKeeper. But, indeed, the CAP theorem still works and Apache BookKeeper tries to do the best to deal with it.
Let’s observe two cases which demonstrate practical limitations and traits of Apache BookKeeper in the regards to ledgers architecture.
Imagine, we want our observers monitor for new ledgers and we would like them to read the data as soon as possible, with lowest delay. Apache BookKeeper assigns 64-bit long identifier for every ledger and theoretically we can open a new ledger each millisecond, but practically it’s impossible because it will lead to a very high load of Apache Zookeeper which keeps ledgers metadata and thus we meet the practical limitation, from the other hand, let’s say we do it every second and Apache Zookeeper is no more a problem, but now we have a lag of 1 second between data placed and data observed. Sometimes it’s acceptable, sometimes it’s not.
Another example is about objects partitioning. Let’s imagine the performance of the Bookie servers is not enough writting all commit records into a single ledger. Then we can meet the situation with the objects partitioning demand. We try to “clusterize” the objects by splitting all sets to independent subsets of co-dependent objects and if we can do it then we split data writting operations to several ledgers (one for every of sets). Even in successful clusterization we meet several engineering problems like organizing the way to read a subsequence of ledgers related to a specific subset of objects or reading commit records from several subsequences of ledgers into one state database.
Ledger Identifiers and Ledger Metadata Storage Model
Ledgers metadata are stored in Apache Zookeeper. The storage model enables requesting of the information about all the ledgers or iterate over them, but it’s not so easy, sometimes. Imagine, we would like to implement several independent sequences of ledgers over the same Bookie set. It leads us to a situation when we need to develop our own storage model for that subsequential identifiers because Apache BookKeeper doesn’t deal with “sequences” actually. It treats every ledger as independent entity with no relation to other ones. Meeting the situation like that in our task we designed own queue-like structure over Zookeeper which we use to keep “related” ledgers and iterate over them. The other choice is to deploy separate Bookie servers for every task, but it looks as a trick within a single application.
Apache Zookeeper itself constraints additional limitations which must be accounted:
- The whole database must reside in a server RAM. This constraint is important to keep in mind if you are planning to open ledgers often and keep them. Ledger metadata record has quite small footprint but if you deployed low-RAM node for Zookeeper you can meet the situation.
- When Zookeeper parent node has great amount of child elements then node children list request will fail if the total size of data is greater than 1 MB.
Apache BookKeeper deals well with the second problem providing hierarchical ledger manager which organizes flat ledgers identifier space into several levels by splitting 64-bit long identifier to several parts. By default, however, in a bookie configuration flat ledger manager is used which is a bad choice when a lot of ledgers is planned.
Ledger Entry
Ledger Entry is an record of a ledger. Every entry has an unique ledger-wide increasing integer identifier starting from zero. Entry holds arbitrary data in a form of byte array. Entry addition works in either a synchronous or an asynchronous way. An asynchronous way enables better performance and lower latency. An asynchronous callback function is called when an entry associated with operation is placed into a ledger, in ordered way (after previous entry operations are completed).
The three concepts — Bookie, Ledger and Ledger Entry are core elements of Apache BookKeeper and solid understanding of them is crucial for its usage.
Summary
Apache BookKeeper is still under the action of the CAP theorem and thus applies severe constraints to operation. Also, a developer must keep in mind that despite the fact Apache BookKeeper provides the developer with certain guarantiees there are still many ways to breach the expected application behaviour on a client side.
The article is introductionary and doesn’t pretend being full reference manual to Apache BookKeeper. Apache BookKeeper provides an easy way to develop “Hello World” level prototype, but in some cases a lot of additional engineering may take place.