
This article discusses a theoretical foundation for code coverage analysis as well as a practical implementation approach based on the Travis-CI continuous integration system and the Coveralls code coverage analysis tool.
Intentions behind code coverage analysis
Code quality is the cornerstone of any project. Poor code imposes more and more overhead for its maintenance over time, while adding new features takes more time and effort than it would for the quality code. It goes without saying, that criteria for code quality are not universal, they are defined and modified throughout the life cycle of the code.
There are many ways and tools for managing code quality from technical, as well as from organizational perspectives. These tools, when applied by experienced professionals, can ensure compliance with high standards and make the developers proud of their code. These very same tools may in other cases completely paralyze the team by encouraging the developers to dovetail their code for passing excessive checks, at the same time ignoring its more important quality-defining properties.
One of the main tools for maintaining high code quality in commercial software development is code tests. However tests never guarantee code quality. It is both important to implement relevant and efficient tests, and to properly monitor and analyze test results and metrics. This can be done by CI and code coverage analysis systems.
Code coverage analysis is an important technical means for understanding how much of the code base is actually tested by tests. Moreover, it provides additional tools that can be utilized by different team members: developers, QA engineers, code reviewers, project managers.
After being integrated in a project, a code coverage analysis system reports which parts of the code are checked by the tests and which are not. This provides the following important information:
- Total coverage percentage for the whole project (an integral metric that can be used by the project management).
- Total coverage percentage for a class, file, method (an integral metric which allows tracing coverage dynamics across different parts of the project).
- Covered code lines (non integral metric for determining if a particular part of the code is covered by tests).
As mentioned earlier, coverage analysis can be utilized by different team members. Next we’ll discuss possible benefits for particular project roles.
The most efficient way for introducing code coverage analysis is to integrate it in the early stage of the project, before any coding. This will allow full utilization of the tool potential for ensuring quality in the long run.
Developer
Developers implement unit tests, integration tests, and other types of tests for the code they develop. If they use a coverage analysis tool, they can detect the following possible problems:
- bad code design - code with a bad design is difficult to test and to cover by tests;
for example, without proper abstractions for interacting with external services, the code can’t be tested outside of the specific environment; consequently such code is usually avoided by the developers, and this can be detected by coverage analysis;
- dead code - coverage analysis can help detect the code that can’t be tested no matter how hard you try; this code is the first candidate for deletion;
- coverage analysis can assist writing tests; after discovering that the coverage percentage is low you can implement designated tests for covering the uncovered parts.
By covering your code with tests and analyzing the coverage in the described manner, it is possible to ensure code quality both in terms of software design, and in terms of isolation and single responsibility principles. From developer’s perspective these processes can be performed by means of an IDE; IntelliJ Idea, for example, supports both coverage statistics and uncovered code highlighting.
QA engineer
QA engineers often implement automated integration and imitation tests. They can utilize coverage analysis reports in order to implement tests that can’t be done by developers without a specific environment. These environments are usually available for the QA department and might include systems with test data, sandboxes, etc. In this case the QA department can implement their own test suit, then analyze its coverage, and consequently ensure higher total coverage than it is possible to achieve with only developers’ tests, which usually operate only with mock-objects.
Moreover, the QA department can be assigned the responsibility for the initial code review by analyzing test coverage. In case of many uncovered code parts, the QA engineer can reject the code and return it for rework.
Code reviewer
Reviewers can more efficiently detect code entities that are implemented without proper abstraction from the environment, classes with bad design and violations of the single responsibility principle, poorly tested code, all this without immersing into deep analysis, which could save a considerable amount of time and effort.
Project manager
Project managers monitor integral metrics of code coverage in order to understand rate and direction of metric changes, which allows them to better plan next iterations, and to timely identify situations when the code quality declines, which might have a negative effect on mid-term and long-term results of the project team.
One possible development process with code coverage analysis is illustrated by the following picture:
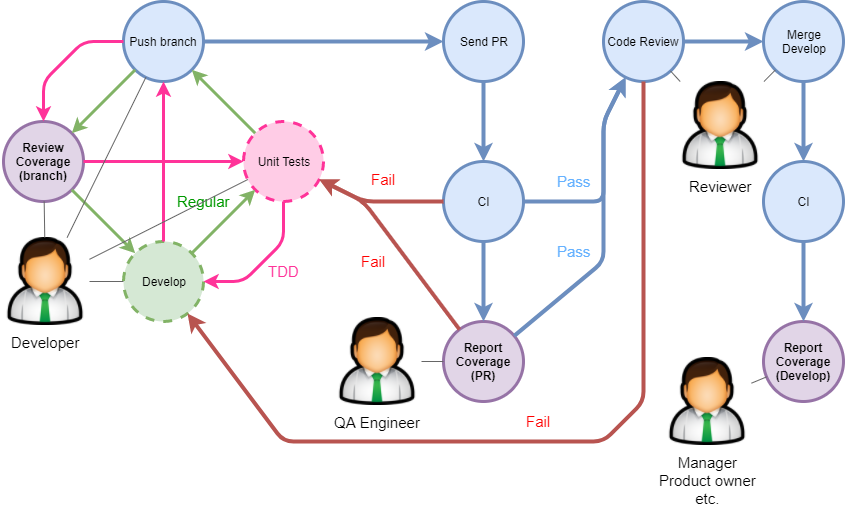
This process is typical for medium and large software development projects. Left part of the image shows development process for a task, utilizing one of the models: unit-test development or TDD, but the cycle includes an additional step for code coverage review. This analysis can be performed both by built-in tools of an IDE and by external tools. There are also coverage analysis steps for QA Engineer and Project Manager built into the process.
Coverage analysis issues
Code coverage analysis is a useful and efficient tool. However, there are some factors that might hinder its application for real projects. Some of the factors are listed below:
- high dependance on the environment and lack of efficient test environment management ecosystem;
- lack of continuous code integration (CI);
- loose test coverage discipline;
- tight project deadlines: tests are not implemented at all, to the disadvantage of mid-term and long-term product quality;
- low qualification of the developers.
These aren’t the only possible reasons determining efficiency of code coverage analysis, but they are the most common.
If the project has no tests, few tests, or low test development discipline, the tool cannot be used. A typical example: a developer (often an under-qualified one) is assigned a task of implementing a PoC of the product in a limited time frame. His first natural impulse is to write at least something that works, and since the job is finished in a couple of days, a week at most, he manages to keep all the details in his head. While carrying out the task, he doesn’t bother himself with code quality, abstraction from environment, etc.
Later this very PoC is expanded to the product level within the confines of the existing design, and the situation is taken for granted. As a result, writing tests becomes a difficult task (a significant part of the code is now even untestable).
If the product owner doesn’t understand necessity of refactoring, if he is not ready to spend money and time on something that doesn’t have tangible results, the long-term impact on the product becomes more dramatic.
Thus it is advisable to start using code coverage in the very beginning of the project by selecting CI and code coverage analysis tools, and agreeing on the development process that will include well-defined criteria for code evaluation in terms of tests and coverage.
At this stage many teams face difficulties with setting up a CI ecosystem that will allow efficient integration for branches and pull requests, and at the same time provide tools for coverage analysis. Many teams attempt coverage analysis integration, but without a convenient tool this analysis is performed at best sporadically, and in the worst case scenario only upon requests of the person concerned.
In other words, without tight integration with the development cycle, coverage analysis can’t be used, or is so inconvenient, that all its advantages are neglected. An important factor for its application is presence of the accessible tool for visual analysis, that is available and user-friendly for a wide range of stakeholders.
Next we suggest tools that allow efficient integration of CI and coverage analysis system with a development process that uses a GitHub repository.
Continuous integration and code coverage analysis with Travis-CI and Coveralls
Travis-CI is a well-known system for continuous integration, that can be easily used alongside with the Github version control system.
Coveralls is a less known system for code coverage analysis, that can be integrated with Travis-CI and allows performing coverage analysis without the need to deploy additional infrastructure (however there is a way to deploy it on the developer’s side).
These systems allow free CI and coverage analysis for public GitHub repositories. This is handy both for assessment, as well as for open-source projects. If a private repository should be integrated, the paid subscription is required.
Travis-CI and Coveralls can be integrated with GitHub as shown in the following picture:
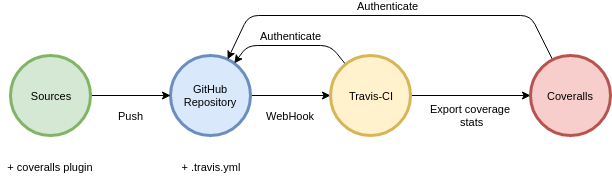
As can be seen from the diagram, the following integration steps are required:
- authorize Travis-CI and Coveralls to have access to a GitHub account;
- choose a repository for CI and coverage analysis to be activated for;
- configure options for the repository by using web interfaces for Travis-CI and Coverall (using defaults is enough for most cases);
- create .travis.yml file with test running directives, including export to Coveralls.
As an example let’s look at the repository of one of our open-source projects: bwsw/imp, which already has integration configured. This project is implemented in the Scala programming language and uses SBT for building. The following are the changes we have done to the project in order to integrate Travis-CI and Coveralls.
Other development technologies need similar actions to be performed, specific for the platform in question. Additional details can be found in the documentation pages for Travis-CI and Coveralls.
Adding plugins for coverage analysis with Coverall to SBT
We added the plugins to project/plugins.sbt:
addSbtPlugin("org.scoverage" % "sbt-scoverage" % "1.5.0")
addSbtPlugin("org.scoverage" % "sbt-coveralls" % "1.1.0")
Adding the scoverage-runtime dependency to build.sbt
This dependency is required for running tests and analyzing coverage directly in IntelliJ Idea.
libraryDependencies += "org.scoverage" % "scalac-scoverage-runtime_2.12" % "1.3.0"
Adding test specification file for Travis-CIля Travis-CI
In the project root directory we created a .travis.yml file with the following contents:
language: scala
jdk: oraclejdk8
scala:
- 2.12.2
script: "sbt clean coverage test"
after_success: "sbt coverageReport coveralls"
Pay attention to the lines with script and after_success. SBT coverage test generates a report for
test coverage. If all the tests are successful, the results are loaded into Coveralls by the coveralls plugin.
Consequently, all the actions are performed by Travis-CI, and Coveralls only receives the coverage analysis.
As a result, for every code push in branches and for pull requests, Travis-CI will perform CI of the project, and the coverage analysis results will be loaded into Coveralls. To see the example report for the IMP project, open the project page in Coveralls.
Coveralls interface shows in a convenient manner both integral metrics, and covered and uncovered parts of specific files. Navigation between different builds allows analysis of the metric change dynamics.