When using DC/OS in scalable systems, tens or even hundreds of servers are often used. As necessary or in emergency situations, the nodes reboot, in this case the DC/OS frameworks determine the unavailability of tasks and start them on other live nodes or wait when the disconnected nodes are online again and restart the stopped tasks on them.
Sometimes this leads to the appearance of tasks in exotic states that can not be removed by both UI and DC/OS CLI tools.
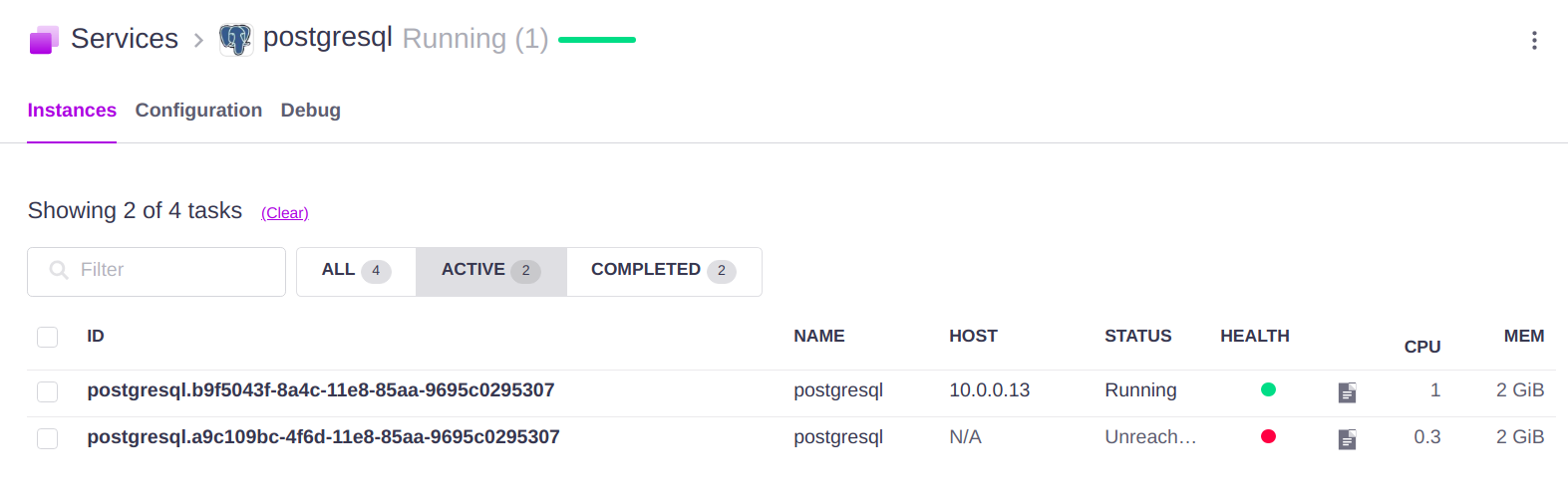
DC/OS is built on top of Apache Mesos, which uses Apache Zookeeper as its built-in database, so we assumed that the records for such tasks are simply “stuck” in the Zookeeper and need to be removed. However, we found that there are no such records in Zookeeper. Moreover, DC/OS CLI also does not see the record data, they are only present in the DC/OS REST API.
We assumed that DC/OS simply caches these incorrect entries somewhere within the Master process. To test the hypothesis, we performed a one-by-one reboot of each master process:
# systemctl restart dcos-mesos-master
This resulted in the disappearance of data records from the REST interface and UI. It should be noted that these tasks do not dispose of resources and do not pose a threat, however, they dirty the environment and can mislead the system administrators, so cleaning them is useful.
Remember that restarting Master processes is safe only in a failover deployment of DC/OS, and in the case of a deployment with a single node in the Master role, it will result in a temporary unavailability of the service.
Please, share the post with friends if you like it.