Why do we love InfluxDB? That’s because this is an outstanding product that allows working with time series easily. It provides high performance for both data insertion and retrieval. It offers us a SQL-like query language with convenient functions for processing time-series data (for example, a derivative of values). It is supported by convenient visualization tools, such as Grafana. It provides continuous queries that handle data aggregation on the fly. And also for the fact that one can get started with InfluxDB within a couple of hours.
Why do we avoid using InfluxDB in projects? That’s because the cluster solution is not open-source. One has to pay for scaling and fault tolerance by purchasing a license. There is nothing wrong with this, however, in the concept of developing software based on free software, when all infrastructure components must be published under open licenses, there is no place for commercial products. As a result, the introduction of InfluxDB in the critical places of information systems is impossible.
It’s interesting – Apache Cassandra, Kafka, HDFS, Elasticsearch, and many others provide clustered solutions for free which leads to their greater adoption in the projects.
In this article, we will illustrate how to use a supplementary Apache Kafka cluster to implement the scalability and fault tolerance of InfluxDB for popular use cases, without purchasing a commercial license for the InfluxDB cluster.
Please, note that in the context of this article you can use any other message broker instead of
Apache Kafka. But since our company often usesKafka, andKafkais already present in a product where the solution has been applied, we’ve decided to use this system in this article. You can useRabbitMQor another solution you are familiar with. However, in the case of this architectural solution,Kafkahas a number of advantages.
The idea for writing this article has grown from the solved problem of the InfluxDB server availability for one of the services. We decided to summarize our experience so that other developers could get to know a successful approach to solving the problem.
System Requirements
To begin with, let’s define the system requirements that are important to consider when implementing this architectural solution.
Isolated readers and writers. In classical DBMSs, the same agents often act as readers and writers. Fortunately, this is not about TSDB in most cases. In this article, we expect that a part of processes in an information system is readers who simply perform data sampling operations, while the other part is writers who just write data. There is no connection between these groups of processes ideally or it is weak. It is important that readers do not count on the productivity of writers, data processing takes place in a fully asynchronous mode.
The approaches of this article will not work in case the same agents are both readers and writers, and on the same data. But this use case is rare with TSDB storages.
Processing delay tolerance. A message broker adds a delay in the processing that can take from milliseconds to seconds, depending on its performance, settings, and current load. If such a delay is critical, the approach cannot be used. On the other hand, the message broker can help you to work more conveniently with the insertion of large record blocks in InfluxDB that can improve the overall performance.
Data partitioning (only for the horizontal scaling task). Data can be partitioned into groups – ideally, the objects are completely isolated, in a more general case, the objects can be divided into subgroups which are isolated.
Solved Tasks
Within the proposed architecture, we will be able to achieve the improvements for:
- High-availability cluster – the fault tolerance, higher data access performance with the redundancy;
- High-performance cluster – the fault tolerance, higher data access, and data insertion performance with the redundancy and sharding.
High-Availability Architecture
This architecture is pretty simple. Its model is shown in the figure below:
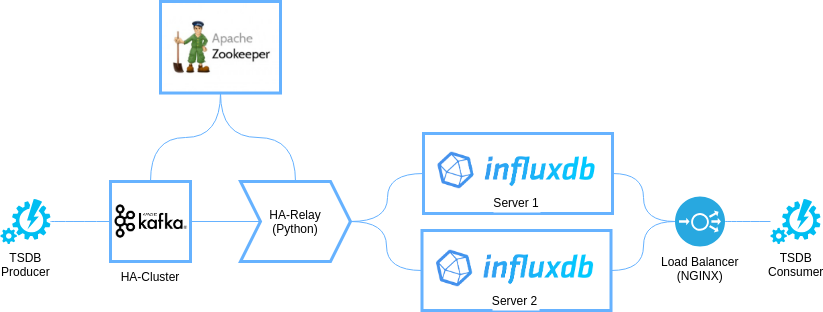
At the same time, from the perspective of components placement on physical or virtual nodes, the architecture will be represented by a three-node configuration shown below:

The easiest way to deploy this topology is to use Docker in the Swarm or independent mode. However, you can deploy the applications in the other way – without containers, in Kubernetes, OpenShift or DC/OS environment. Components which are outlined with dashes are optional and can be excluded from the minimal configuration. However, if you prefer the unified deployment, it may be convenient to add them to your Ansible, Chef or other automated configuration tools.
The Architectural Basis
The architecture is based on a fault tolerant cluster built with Apache Kafka and Apache Zookeeper. These are two widely known and reliable software components that make the proposed architecture highly reliable and productive.
Apache Zookeeper. It is used directly by Kafka as it’s required dependency component. In addition, Zookeeper will be used as a distributed lock service for HA-Relay – to avoid multiple recordings of the same data in InfluxDB we need to ensure that only one HA-Relay service is running at a time. To implement locking a locking recipe must be used.
Apache Kafka. In the architecture, Kafka performs the function of a highly reliable and highly efficient FIFO buffer for pre-accumulating time series records that will be loaded into InfluxDB. As we noted earlier, you can use another queuing service instead of Kafka as well as completely eliminate it. However, we recommend using Kafka because its unique features help to achieve:
- data batching before loading into
InfluxDB; - data rebuild in the case of
InfluxDBstorage destruction; - transactions support when the data load from agent to
Kafka(using transactions or an idempotentKafkaproducer), and further – idempotent load fromKafkaintoInfluxDBby the use of theKafkarecord timestamp.
In this topology, it’s enough to use only one Kafka topic with threefold replication.
HA-Relay Implementation
This element of the architecture is implemented using a convenient programming language. Its purpose is to read the data from Kafka and to send them into several independent InfluxDB databases, thereat it is important to guarantee the following characteristics:
- to avoid writing of duplicate data (only one
HA-Relayworks in a cluster at a time), it is achieved by the use of theZookeeperlock recipe; - the data retrieved from
Kafkaare inserted intoInfluxDBin batches to minimize the load; - the time field for every
InfluxDBrecord is set by the time specified in aKafkamessage, which allows you to avoid time distortion, especially in caseHA-Relayprocessing lags or temporary outages; - each data record added into
InfluxDBis augmented withApache Kafkafields:topic,partition,offset,timestamp. This helps overwrite the previous records avoiding record duplicates when the same data element inserted one more time.
By implementing HA-Relay supported the listed requirements, one can be sure that the data in InfluxDB will be eventually consistent. At certain points in time, the system may show a processing lag (delay), but the data will not contain incorrect timestamps or gaps (except for the synchronization period).
Servers Synchronization After The Failure
If one of the InfluxDB servers fails, then a situation arises when the data are delivered into the remaining servers, but they are absent on the failed server. That failed server will return inconsistent data after the start. For the synchronization, one has to implement a separate protocol that handles this case in a special way.
The protocol must take into account the following points:
- while the synchronization is incomplete, the
InfluxDBlagging server should be unavailable for clients – it must be excluded fromNginxbalancing, which can be done both with the use ofIptablesorNginxreconfiguration; - synchronization should include the data load from the moment the
InfluxDBserver crashed to the currentKafkatopic offset saved inZookeeperat the moment the synchronization starts.
It is convenient to use a one-time launched application that will perform the synchronization procedure.
Nginx Load Balancing
InfluxDB uses an HTTP-based protocol, so Nginx can be utilized to implement load balancing between InfluxDB servers. That achieves traffic balancing improving application performance and ensuring fault tolerance when one of the servers fails.
Scalable Architecture
The second option is scalable, fault-tolerant architecture. This is a more sophisticated topology based on the previous architecture. The model is shown in the figure below:
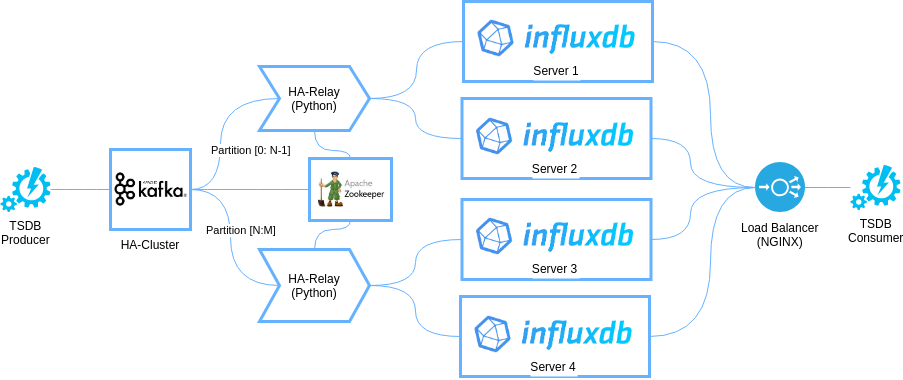
Scaling is based on data sharding performed by splitting the entire dataset into disjoint groups and applying a hashing algorithm to the key fields that maps the entire set of object keys to the set of Kafka partitions. In this architecture, we create a Kafka topic with several partitions. Partition number reflects the performance expectations – one partition is used per each InfluxDB shard. Each shard can be deployed as fault tolerant in that case it consists of two InfluxDB servers that replicate each other.
HA-Relay Implementation
In this architecture, HA-Relay does not operate on all Kafka partitions, but only on those allocated to it. It enables linear scalability. An engineer simply adds one HA-Relay and a pair of InfluxDB servers per each Kafka partition building a data shard.
Nginx Load Balancing
Within the architecture, using Nginx server only will not be enough for successful load distribution. One has to look inside the requests to understand what objects they are touching, so to route them to the servers storing the required objects. It can be achieved with a microservice, which is aware of the hashing method applied to distribute objects. In the Nginx balancer, one should use the Influx access scheme of the http://server:8XXX type, where XXX stands for a partition number, for example, 001.
Limitations
In this architecture, queries that touch objects from different shards cannot be used. After the data from the shards retrieved, further data management must be implemented at the application level. This limitation prevents the use of existing tools such as Grafana, for requests which perform operations affecting the entire data set, not just the data in one of the shards.
Conclusion
We have considered two practical architectures that can significantly increase the InfluxDB applicability in highly available systems that use open-source components only. These architectures are widely applicable, however, their use involves additional engineering solutions that require separate implementation and management tools.
When implementing these architectures, all system requirements should be taken into account since in many cases limitations may take place preventing the solution implementation.
If you like this post and find it useful, please, share it with friends.