Apache Spark is a quite popular framework for massive scalable data processing. It is the heart of big-data processing systems for many companies which is very convenient for small computations in a single workstation, a corporate server or a high-performance cluster with thousands of nodes. Apache Spark has a very sophisticated design and, at the same time, an easy development model for software developers, which is especially important on early stages of the product adoption. The most attractive feature of Spark is that when the computations are designed well, Spark utilizes all the available compute capacity. Engineers don’t care about parallelization, multithreading, multiprocessing, and other stuff – all the magic happens inside Spark.
However, there are anti-patterns for Apache Spark which sometimes make its usage inefficient. The most common reason for that is the purpose Spark is created for – high-performance big-data computations. Literally, this means that Spark is optimized for volume rather than for latency. Its design is very sophisticated and as a consequence, it leads to very slow initialization which takes several seconds when the task starts. After the initialization completes, everything works blazing fast if designed well.
Below, you can see a typical diagram for Spark computations performance. In the example computations, the input parquet files exported from Vertica are transformed into a resulting parquet file.
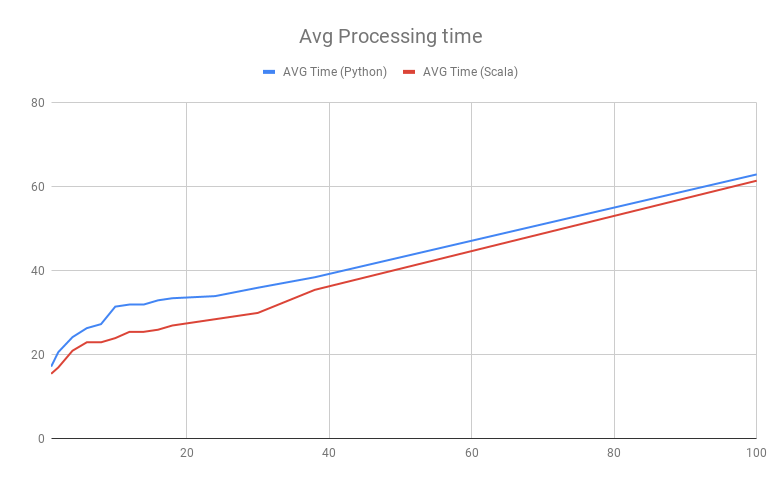
The horizontal axis defines the amount of input parquet shards which are basically a single parquet table like data/key={v}/part.parquet. The vertical axis shows the processing time required for the task to complete. The most important details are at the left:
- even if Spark processes 1 input shard, the time to process is about 18 seconds;
- the time is almost the same for Spark Scala and PySpark.
Sliding over the diagram to the right you may find that the time increases greatly until all the cores of the server (12 cores in our case) are used, after that moment the task execution time grows, but less intensively than before. And it’s what we mean when we say that Spark is designed for a bandwidth of the computation rather than for a latency. Native Scala behaves a little bit better than PySpark but follows the same trendline though.
To rephrase: a bootstrapping application takes almost 18 seconds doing nothing. There are very few things which you can improve there, but still, they are. First, let’s observe two different task definitions which can be met in practice:
- The purpose is to handle a bunch of pretty small amount of data in NNN seconds;
- The purpose is to handle some bunches of the same data for MMM seconds.
These tasks can look similar but they can differ a lot. The difference is heavily connected with the relation of the Spark bootstrap time and the data processing time. Basically, the rule is to use Spark only if the data processing time is significantly greater than the time which Spark takes to initialize. Actually, there are a lot of considerations regarding the previous recommendation, but the rule of thumb is to use Spark when you need to optimize overall processing capacity but not the time that the processing of sequential single elements takes. If the processing time naturally much higher than the initialization time, then the things just work. If you have comparable times, then you probably will not scale well if you don’t have concurrent tasks which can be launched and evaluated in parallel.
In our practical case, the customer wanted to process a relatively large amount of data within the deadline of 20 seconds, while the next amount was not ready for the processing until the first one was processed. So, for our case, Spark was not a perfect technology because it regardless of scaling factor we could not overcome the initialization limitations for every single sequential task.
Still, there are a couple of approaches which help to deal with long bootstrap times and make small tasks run faster. Now we observe them:
Persistent Context
Usually, when Spark job is created it creates Spark Context within which it is executed. Context initialization is a very, very slow process. There is an approach which keeps Spark сontext initialized. The most well-known one is implemented in Spark Job Server. Spark Job Server is a standalone service which connects to a Spark cluster (or embedded standalone Spark) and manages Spark jobs. The product supports the creation of persistent contexts which are kept until explicit removal. The persistent context easily decreases the bootstrap time for several seconds. The idea is pretty straightforward – while Spark Job Server is operational, Spark context is reused by the task which is launched within it.
The diagram above demonstrates computation results with Spark Job Server. For a classic Spark jobs execution, the bootstrap time is even higher.
Previously Uploaded Artifacts and Code
Spark tasks are often launched by Spark submit which takes all the dependencies and submits them into Spark cluster where the task is executed. If artifacts include hundreds of megabytes of binaries, then the task submission can easily add several seconds. The solution is to place all required artifacts and reusable data on every node or inside the Docker image which is used to roll Spark nodes to minimize the size of submission. It also may be beneficial to implement Spark job in the client mode rather than the cluster mode.
Always-on Client-Mode Job
This approach helps to decrease the bootstrap time even further. When implementing the approach you create a Spark client-mode application which is always launched and the computations are triggered by an external event. This helps to achieve two outcomes:
- Spark context is persistent;
- All Spark structures inside JVM are always initialized and ready for data processing.
When this approach is implemented the first run is still pretty slow as it takes time to initialize everything, but subsequent runs are much faster. Take a look at the following diagram to find how always-on PySpark is compared to Spark Job Server results:
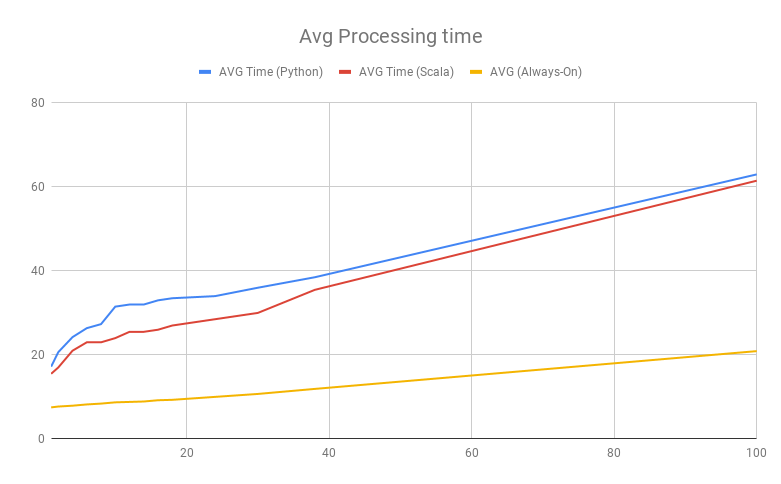
Despite significant speed improvement, it still takes several seconds to run preparations, however, it’s much faster than when other methods are used.
Always-on Example Implementation
Below you can find a PySpark example for Always-on implementation which can be used to decrease the initialization time.
from pyspark.sql import Window
from pyspark import SparkConf, SparkContext, SQLContext
import pyspark.sql.functions as F
import time
import tornado.ioloop
import tornado.web
def do_compute(dataframes):
# do Spark computations
return dataframes
master = 'local[*]'
sc_conf = SparkConf().setAppName(__name__).setMaster(master)
sc_conf.setAll([
('spark.sql.shuffle.partitions', '32'),
('spark.executor.cores', '16'),
('spark.cores.max', '16'),
('spark.driver.memory','8g')])
sc = SparkContext(conf=sc_conf)
sql_context = SQLContext(sc)
def main(master, test_ids):
start_file = time.time()
df = sql_context.read.parquet('data/in')
res = do_compute(df)
res = res.repartition(1)
res.write.mode('overwrite').parquet('data/out')
end_file = time.time()
print("File %s (%.1f seconds)" % (file, end_file - start_file))
return end_file - start_file
class RunHandler(tornado.web.RequestHandler):
def get(self):
tm = main(master)
self.write('OK %.1f secs\n'% tm)
app = tornado.web.Application([
(r'/', RunHandler)])
if __name__ == '__main__':
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
As you can see, the approach is driven by a Tornado web service which triggers the computation upon request. In the example, the request doesn’t get parameters, but in a real life, you may find that it’s convenient to pass parameters which define exact behavior.
The Conclusion
Summing up, if you need to run low-latency jobs with a relatively small amount of computations try avoiding Spark, if you still want using it, implement the persistence and other mentioned enhancements to decrease the initialization time. You also have to play with Spark options to decrease the initialization time and increase the performance. We recommend starting with spark.sql.shuffle.partitions parameter. Spark is a very convenient universal computation engine, but the universality does not make it a perfect one for certain tasks. Always monitor how the initialization time is compared with the computation time, sometimes Spark is not the right technology for scalable computations.