Apache Spark – довольно популярная среда для масштабируемой обработки данных. Для многих компаний это сердце систем обработки больших данных. Spark в равной степени удобен для вычислений на одиночной рабочей станции, одиночном сервере или высокопроизводительном кластере с тысячами узлов. Apache Spark имеет очень сложную архитектуру и, в то же время, простую модель разработки, что особенно важно на ранних этапах изучения продукта. Наиболее привлекательной особенностью Spark является то, что, когда вычисления хорошо спроектированы, Spark использует всю доступную вычислительную мощность. Инженеры не тратят время на организацию распараллеливания, многопоточности, многопроцессорной обработки и прочего – вся магия происходит внутри Spark.
Тем не менее, для Apache Spark существуют антипаттерны, которые делают его использование неэффективным. Основной причиной тому является цель, для которой Spark был создан – высокопроизводительные вычисления на больших данных. В буквальном смысле это означает, что Spark оптимизирует пропускную способность обработки, а не время обработки одиночного задания с минимальной задержкой. Он имеет сложную архитектуру, что, приводит к очень медленной инициализации, которая при запуске задачи может занять несколько секунд. После завершения инициализации, при правильном проектировании, все работает быстро.
Ниже представлен график вычислений с помощью Spark. В задании, использованном для построения этого графика, вычисления преобразуют входные Parquet-файлы в целевой Parquet-файл.
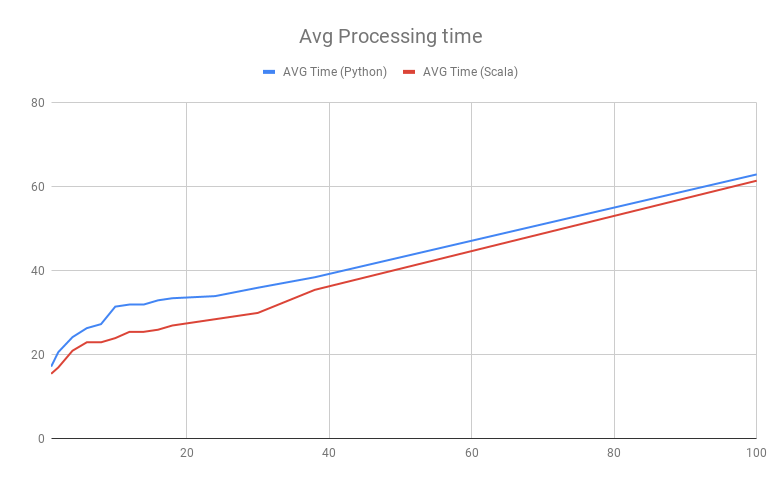
По оси Х представлено количество обрабатываемых заданием входных Parquet-сегментов, которые представляют собой единую партиционированную таблицу вида data/key={v}/part.parquet. По оси Y указано количество времени, необходимое для выполнения задачи. Наиболее интересная информация находится в левой части графика:
- даже если Spark обрабатывает только один сегмент файла, время обработки составляет около 18 секунд;
- время обработки почти одинаковое для Spark Scala и PySpark.
Если вы будете продвигаться по диаграмме вправо, то увидите, что время существенно растет до тех пор, пока все ядра сервера (у нас их 12) не задействованы. После этого время выполнения задачи растет сравнительно медленно. Именно это и имеется ввиду, когда мы говорим, что Spark спроектирован для вычислений большого объема данных, а не для сокращения времени ожидания. Задание с реализацией на Scala показывает несколько лучшие результаты, чем PySpark, но, в целом, ничем не выделяется.
Исходя из предыдущего графика, можно предположить, что только инициализация приложения занимает почти 18 секунд. Снижение этого времени на практике возможно, но лишь отчасти. Сперва рассмотрим два различных определения цели задания, которые могут встретиться на практике:
- обработать сравнительно небольшой блок данных за минимальное время;
- обработать максимальное количество блоков за минимальное время.
Эти задачи кажутся похожими, но, на самом деле, разница между ними огромна. Она тесно связана с отношением времени начальной загрузки Spark ко времени обработки данных. Общее правило заключается в том, чтобы использовать Spark, только если время обработки данных значительно превышает время, необходимое Spark для инициализации. На самом деле, есть много соображений относительно предыдущей рекомендации, но практическим правилом является использование Spark в случаях, когда нужно оптимизировать общую пропускную способность, а не время, которое тратится на обработку каждого отдельного элемента данных последовательным способом. Если время обработки значительно превышает время инициализации, то все прекрасно работает. Если периоды времени сопоставимые, то вряд ли удастся масштабировать вычисления эффективным способом.
Пример: Требуется, чтобы относительно большое количество данных обрабатывалось за 20 секунд, при этом обработка следующей порции данных должна была начинаться только после завершения обработки предыдущей. В этом случае Spark не является оптимальной технологией, так как независимо от коэффициента масштабирования, мы не сможем преодолеть ограничения инициализации для каждой последовательной задачи.
Все же, существует три подхода, которые помогают сократить время загрузки и ускорить выполнение небольших задач.
Постоянно загруженный контекст
При создании задания Spark создается SparkContext, в котором оно выполняется. Инициализация контекста – очень, очень медленный процесс. Существует подход, который позволяет поддерживать контекст Spark загруженным в памяти постоянно. Самая известная реализация – Spark Job Server. Это отдельный сервис, который подключается к кластеру Spark (или встроенному автономному Spark) и управляет заданиями Spark. Продукт поддерживает создание постоянных контекстов, которые используются до тех пор, пока не будут явно удалены. Постоянный контекст уменьшает время начальной загрузки задачи на несколько секунд. Идея довольно проста – во время работы Spark Job Server, предварительно инициализированный контекст Spark многократно используется для выполнения заданий. Особенно это хорошо для родственных заданий, которые используют преимущества общего контекста.
На приведенном ранее графике показаны результаты вычислений с использованием Spark Job Server с повторно используемым контекстом. Выполнение заданий Spark с загрузкой с нуля будет занимать еще большее время.
Предварительная загрузка артефактов и кода
Задачи Spark часто запускаются с помощью Spark submit, который отправляет все зависимости в кластер Spark, где выполняется задача. Если артефакты содержат сотни мегабайтов двоичных файлов, то отправка задачи может занять дополнительные несколько секунд. Решение заключается в том, чтобы разместить все необходимые артефакты и данные на каждом узле или внутри Docker-образа, который используется на узлах Spark, чтобы минимизировать размер отправляемых данных. Может быть полезно выполнять задание Spark в режиме клиента, а не в режиме кластера.
Использование постоянно загруженных в память заданий
Этот подход позволяет еще сильнее сократить время начальной загрузки, объединяя два предыдущих подхода. При реализации этого подхода создается приложение Spark в режиме клиента, оно всегда запущено, а вычисления инициируются внешним событием. Это помогает достичь двух целей:
- контекст Spark является постоянным;
- все структуры Spark внутри JVM постоянно инициализированы и готовы к обработке данных.
При реализации подхода первый запуск все еще происходит довольно медленно, так как для инициализации всех процессов требуется время, но последующие запуски происходят намного быстрее. На графике ниже показаны результаты сравнения времени обработки для задания PySpark при использовании данного подхода и подхода Spark Job Server:
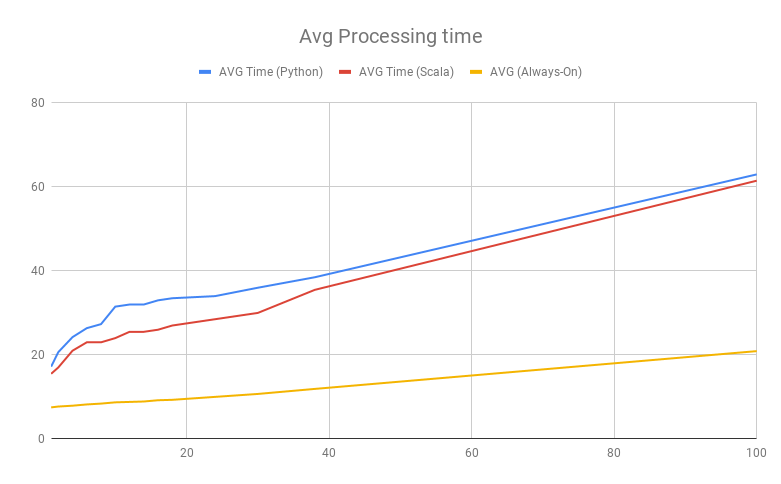
Несмотря на значительное улучшение скорости, подготовка к запуску все еще занимает несколько секунд, однако это происходит намного быстрее, чем при использовании других методов.
Пример реализации
Ниже представлен пример реализации в PySpark, который позволяет уменьшить время инициализации.
from pyspark.sql import Window
from pyspark import SparkConf, SparkContext, SQLContext
import pyspark.sql.functions as F
import time
import tornado.ioloop
import tornado.web
def do_compute(dataframes):
# do Spark computations
return dataframes
master = 'local[*]'
sc_conf = SparkConf().setAppName(__name__).setMaster(master)
sc_conf.setAll([
('spark.sql.shuffle.partitions', '32'),
('spark.executor.cores', '16'),
('spark.cores.max', '16'),
('spark.driver.memory','8g')])
sc = SparkContext(conf=sc_conf)
sql_context = SQLContext(sc)
def main(master, test_ids):
start_file = time.time()
df = sql_context.read.parquet('data/in')
res = do_compute(df)
res = res.repartition(1)
res.write.mode('overwrite').parquet('data/out')
end_file = time.time()
print("File %s (%.1f seconds)" % (file, end_file - start_file))
return end_file - start_file
class RunHandler(tornado.web.RequestHandler):
def get(self):
tm = main(master)
self.write('OK %.1f secs\n'% tm)
app = tornado.web.Application([
(r'/', RunHandler)])
if __name__ == '__main__':
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
Как видно из примера, подход основан на веб-сервисе Tornado, который запускает вычисления по запросу. В приведенном примере запрос не принимает параметры, но в реальной жизни полезно передавать аргументы, которые будут определять поведение задания, например, расположение входных и выходных данных.
Заключение
Подведем итог: если необходимо запускать задания с малой задержкой при сравнительно небольшом количестве вычислений, попробуйте обойтись без Spark. Если все же хочется его использовать, внедрите метод постоянного контекста и другие улучшения, описанные в статье, чтобы уменьшить время инициализации. Также, чтобы сократить время инициализации и повысить производительность, можно пробовать изменять настройки Spark. Мы рекомендуем начать с параметра spark.sql.shuffle.partitions.
Spark – очень удобный универсальный вычислительный фреймворк, но универсальность не означает, что он идеально подходит для всех задач. Всегда следите за тем, как время инициализации соотносится со временем вычислений, не во всех случаях Spark подходит для масштабируемых вычислений.