The Problem of Biometric Identification On Video Streams
Video data is a universal format for biometric identification. When using video, the chance of forgery of biometric data decreases, it becomes possible to carry out non-cooperative identification, when the person being identified is not required to actively participate in the identification process. The person identification problem can be solved for two cases:
- the person to be identified is known to the system, the database stores a reference photograph or a set of photographs that were obtained in a different way with the participation of the person;
- the person to be identified is not known to the system in advance; upon initial detection, the system selects the best photo and adds it to the database, after which identification is made with respect to the added photo.
The first case is much easier to implement than the second since the database is formed by an external agent, which is independently responsible for the quality and representativeness of the data, the system only has to compare the found faces relative to the database and give a measure of their similarity.
In the second case, the system independently fills the database, which requires it to understand which face extracted from the video stream is suitable for adding to the database, which is suitable for searching, and which should not be used at all. The pipeline responsible for solving this problem includes not only a face detector but also other assessment methods that allow you to make the necessary analysis for making a decision.
The FStreamID product developed in our company allows for high-speed identification and re-identification of persons by faces and is suitable for solving both the first task, where the database is fixed and the second, where the database is automatically filled by the system in a non-cooperative mode.
FStreamID Product
The FStreamID product does faces extraction from a video stream, choosing suitable for indexing, which is determined by the correct face pose, lack of blur, sufficient size, lighting, and other parameters. Face data extracted from the video stream can be used in security systems, sales management, and personalized advertising. The search solution gives relevant results also in the case of the presence of masking elements - such as glasses, a hat, a mustache, a mask, as well as resistant to changes in the subject’s age in both directions (aging, photograph of youth), mimic expressions.
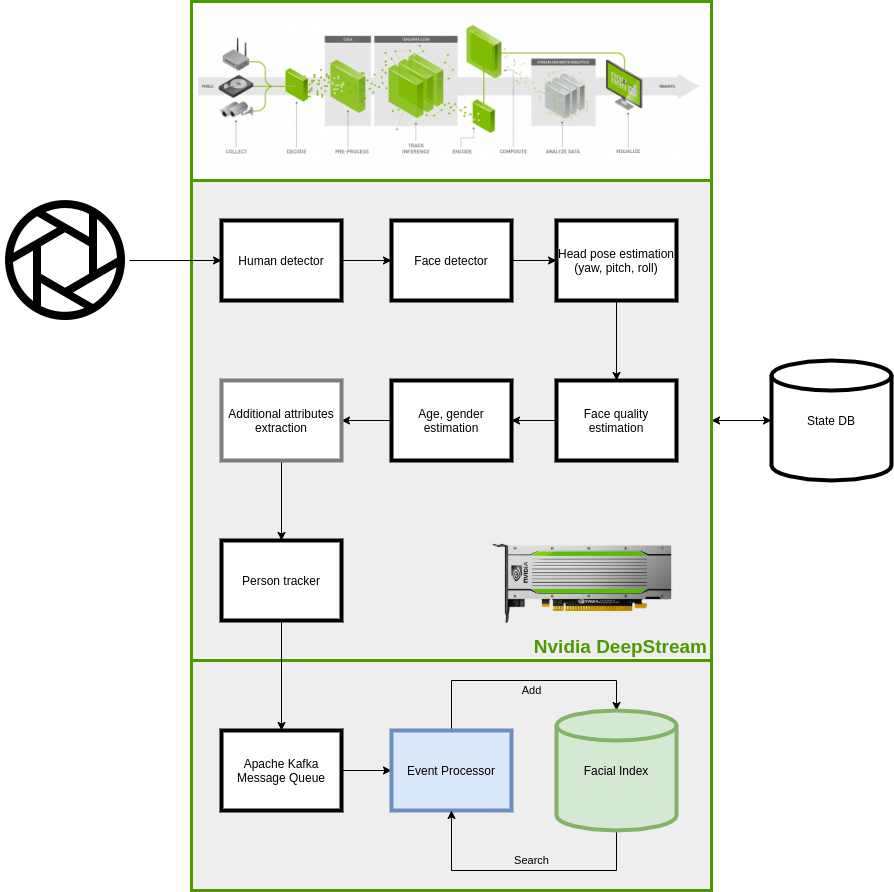
The product enriches facial descriptors with extracted face features like gender and age, as well as face pose (yaw, pitch, roll), quality criteria that determine whether a given face is suitable for indexing, searching in the face index, or shouldn’t be used.
For ease of use, FStreamID integrates with other components through the message bus. Apache Kafka is currently used.
Performance
Bitworks FStreamID runs on Nvidia Volta, Turing, Ampere accelerators. To reach optimal performance, the Nvidia DeepStream framework is used - the only solution on the market that ensures maximum performance of inference applications run on the GPU by reducing the cost of video encoding and decoding, copying frames between CPU and GPU memory, using models optimized for TensorRT.
The FStreamID architecture allows processing from 200 FullHD frames per second on the Nvidia Tesla T4 GPU, that is, more than 8 video streams with a resolution of 1920x1080@25 FPS. H.264, H.265 video decoding is carried out by NVDEC, a dedicated GPU video decoding block.
Stack
The solution is powered by:
- Nvidia DeepStream
- TensorRT
- Python 3
- Apache Kafka
License
The product is being licensed for a certain project. If necessary, the solution is modified to fit the technical requirements of the customer. To receive a commercial offer and a demonstration of the possibilities, contact us using the form below or write to cv@bitworks.software.