OpenCV is a popular framework widely used in the development of products for intelligent video analytics. Such solutions use both classic algorithms of computer vision (e.g. an algorithm for optical flow detection), and AI-based approaches, in particular, neural networks.
Most of such algorithms are resource-intensive and require a large amount of computing resources to process even one video stream in real time. By resources are meant both CPU cores and GPUs, as well as other hardware accelerators.
The camera or other source delivers a video stream with a certain number of frames per second (FPS, Frames Per Second), which must be processed by the analytical platform one by one. Each video frame takes a significant amount of memory, for example, for a resolution frame of 4K with a color depth of 24 bits, a NumPy ndarray array will occupy 24 MB in RAM, so for a 1-second interval these frames will take 729 MB for a 30 FPS stream. With poor performance of the processing pipeline, system may meet a failure situation due to RAM or disk space overflow, or frame loss. Thus, the pipeline must be efficient enough to be able to process every single frame within certain amount of milliseconds (e.g. 33 ms for a video with 30 FPS).
Basic Solution
A simple approach to building a processing pipeline is sequential. In this case, at a standard frame rate of 30, the pipeline must be able to process each frame in 1/30 of a second (33 ms). If pipeline can achieve such numbers, one must stay with this simple architecture. A simple example pipeline from OpenCV documentation successfully processes a frame in 1/30 of a second on any modern equipment:
import numpy as np
import cv2
cap = cv2.VideoCapture(0)
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Display the resulting frame
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
In the case when a single-process linear pipeline is enough, scaling is trivial – one simply to add computing resources and balance the launch of processing pipelines so to not overload the CPU, GPU or hardware accelerators.
Often, however, the operating time of the pipeline fluctuates or takes more time to process the frame than allowed, which can depend on the number of analyzed objects and events occurring in the frame. The operating time of the pipeline can vary within wide limits, for example, in our solution for facial recognition, one of the steps takes the following time on the device **Nvidia Jetson Xavier **:
- single face in the frame:
2.4 ± 0.18 ms; - five faces in the frame:
10.01 ± 0.44 ms.
As one can see, time grows linearly as the number of persons. This is an example of an algorithm whose execution time depends on the contents of the frame. If there are such algorithms, the processing time of the frame may go beyond the desired timeframe, which leads to a delayed processing or loss of frames. As a result, there is a need for the distribution and decomposition of work between executors. They form a distributed processing network graph with nodes providing the processing of some part of the general algorithm.
For example, each of the five faces found in the frame can be processed on a single node in 2.4 ms, while the graph itself can introduce an additional fixed delay due to the cost of transmitting data between its nodes.
Scalable Architecture Based on ZeroMQ Push-Pull Pattern
ZeroMQ is a high-performance data bus built on standard network sockets (sockets on steroids) that implements a number of patterns for distributed processing and communication. The push-pull pattern fits well for building scalable real-time processing pipeline. The ZeroMQ documentation demonstrates the pattern in the following image.:
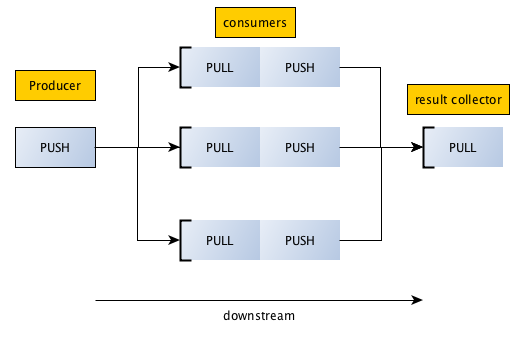
The data flow from left to right, somewhat similar to the MapReduce pattern, which is often used when processing big data. In this case, the middle part (consumers) is scalable.
It is worth noting that the pipeline can be extended further using special ZeroMQ “devices”. A Streamer device should be used for this pattern. In this article this feature of ZeroMQ is not used.
ZeroMQ-based Pipeline Implementation
Let’s learn how one can redesign the pipeline presented in the example above in a scalable way with ZeroMQ. To do this, we will split it into 3 parts:
- video decoder;
- BGR → Gray handler;
- visualizer.
Video Decoder
The decoder has a very simple design: the video is parsed into frames that are transmitted via push-pull to the handler. As long as no handlers are registered, the decoder is in a locked state. It starts provide frames when at least one handler appears. If there are several handlers, the decoder evenly distributes frames between them. In the example, the video is transmitted with an additional time stamp to demonstrate the introduced delay.
The example uses a web camera that generates the video stream
640x480 @ 30FPS.
import cv2
import zmq
from time import time
cap = cv2.VideoCapture(0)
context = zmq.Context()
dst = context.socket(zmq.PUSH)
dst.bind("tcp://127.0.0.1:5557")
while True:
ret, frame = cap.read()
dst.send_pyobj(dict(frame=frame, ts=time()))
BGR → Gray Handler
The handler receives the frame, converts it to grayscale mode and sends it further down the pipeline to the visualizer. One can run as many processors as required, they evenly distribute the incoming load among themselves. Thus, one can scale the pipeline horizontally, and the processing time of each frame is no longer a critical parameter.
import cv2
import zmq
from time import time
context = zmq.Context()
src = context.socket(zmq.PULL)
src.connect("tcp://127.0.0.1:5557")
dst = context.socket(zmq.PUSH)
dst.connect("tcp://127.0.0.1:5558")
count = 0
delay = 0.0
while True:
msg = src.recv_pyobj()
ts = msg['ts']
frame = msg['frame']
tnow = time()
count += 1
delay += tnow - ts
if count % 150 == 0:
print(delay/count)
delay = 0.0
count = 0
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
dst.send_pyobj(gray)
Visualizer
Visualized displays incoming frames in a window.
import cv2
import zmq
context = zmq.Context()
zmq_socket = context.socket(zmq.PULL)
zmq_socket.bind("tcp://127.0.0.1:5558")
while True:
frame = zmq_socket.recv_pyobj()
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
On a laptop with a CPU i5-6440HQ, the introduced delay for decoder → handler step was about 4 ms (640x480 @ 30FPS) on the local loop interface :
0.004144287109375
0.003949470520019531
0.004002218246459961
0.0038284858067830405
0.003976351420084636
0.004110925992329915
0.004024415016174316
0.003885181744893392
0.0037894550959269207
0.003757945696512858
Thus, the whole chain decoder → handler → visualizer introduces a processing delay of about 8-9 ms.
Important Notes
Multi-node design. When implementing a multi-node design, one must use a routable addresses. Note that the bind method is used only in the decoder and visualizer, while the handler uses the connect method, which allows scaling the number of handlers without the need to launch them on known ip-addresses.
Also, when using routed network addresses, the delay may vary from that obtained at the local loop interface, which depends on the settings of the operating system software stack as well as on the network equipment used.
Network bandwidth. As previously demonstrated, transmitting 4K video between the decoder and the processors requires a bandwidth equal to 6 Gbit/s, so 1 Gbit/s link does not fit, one need to use a link of at least 10 Gbit/s. For a real scalable option, it is worth considering 40 Gbit/s and more performant network stacks or reducing the resolution of the video stream before distribution between the handlers. An alternative approach is to compress the transmitted frames with low latency compression algorithms, like LZ4, which reduces channel capacity costs, but may introduce an additional delay.
Encryption costs. If ZeroMQ is used with data encryption, it also adds both delay and CPU load.
Guaranteed processing. ZeroMQ does not contain a dedicated broker that provides the means for reprocessing. If it’s required to guaranteely process all the frames, one should consider an architecture that supports this model, for example, use the RabbitMQ or Apache Kafka message broker.
Launch without a visualizer stage. If it is not required to combine the processing results into a single sequence, then the chain can be reduced to two steps: decoder → handler.
Processing with dependencies. The presented parallelization model assumes that frames are processed independently, if the processing logic of next frames depends on the processing of previous frames, other acceleration mechanisms must be used.